
Xquery Analysis
Our first analysis graphs was done using Xquery in eXist. We pulled specific elements from our song collections and graphed them into SVGs.
For this graph, we used nested for-loops and if-loops to obtain the song count of the next movie in the loops and store them in a variable to be outputted. Although there is a comprehensive list of songs in the home page, this simple graph shows the total number of songs in each movie in a simple and direct way. This would be very helpful if we were to expand our collection and include songs and movies from Disney's other film franchises.
For this graph, we used nested for-loops to graph the double-dimension chart: the width of the bar indicates the number of songs in the movie, the height of the bar indicates the number of voice actors in the movies. This was an interesting approach as it allows us to understand with a quick glance which movies had the most voice actors (more characters singing) than others.

Network Analysis
To begin the process of network analysis, we first had to prepare our data accordingly from XML to TSV (Tab Separated Values) to allow us to then use the program Cytoscape to generate a network of relationships between our elements. Here is a gallery of the networks we were able to generate: (Click on each picture to interact with the network.)
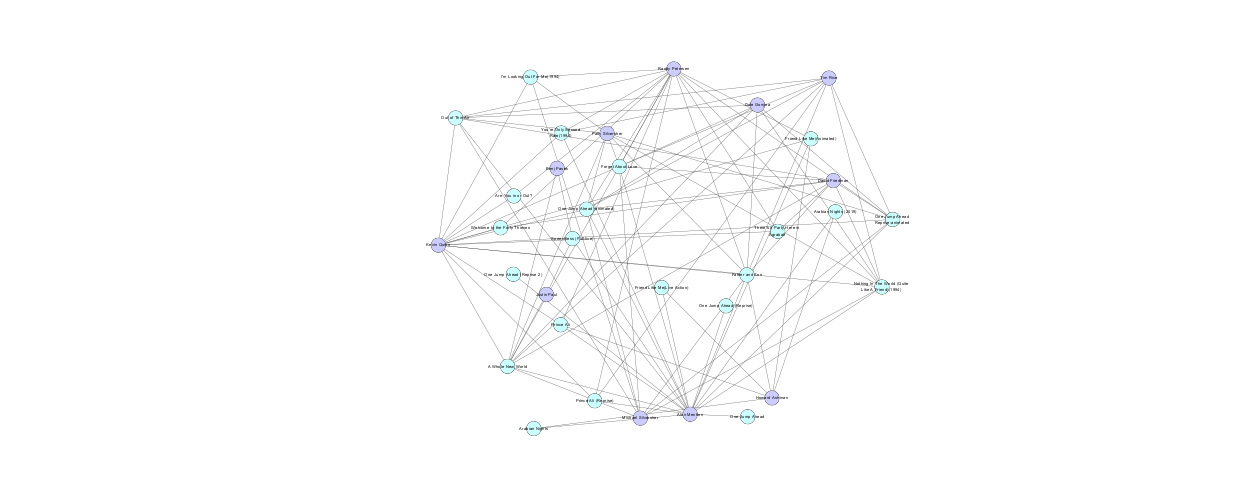
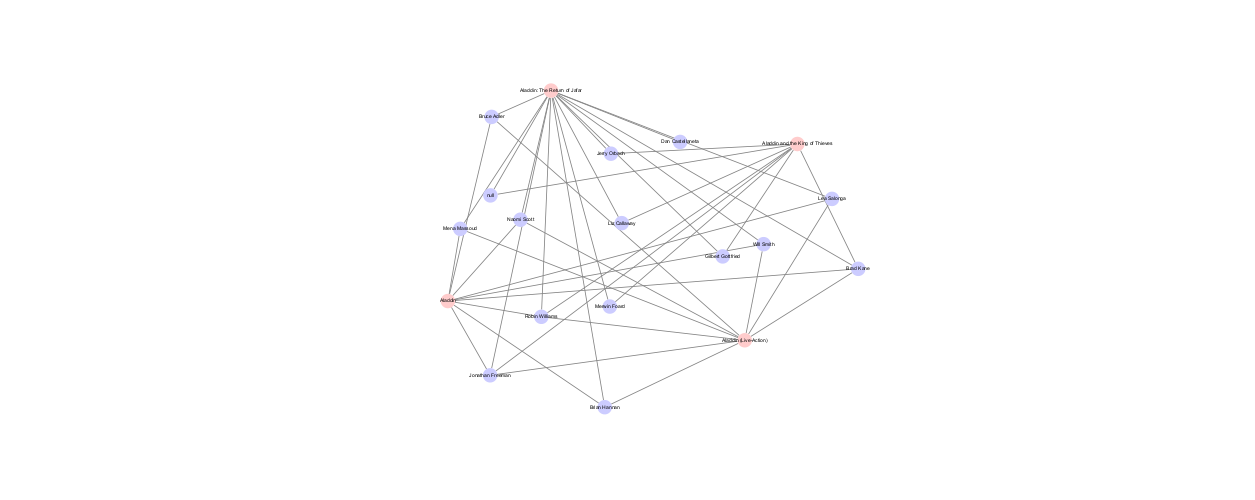
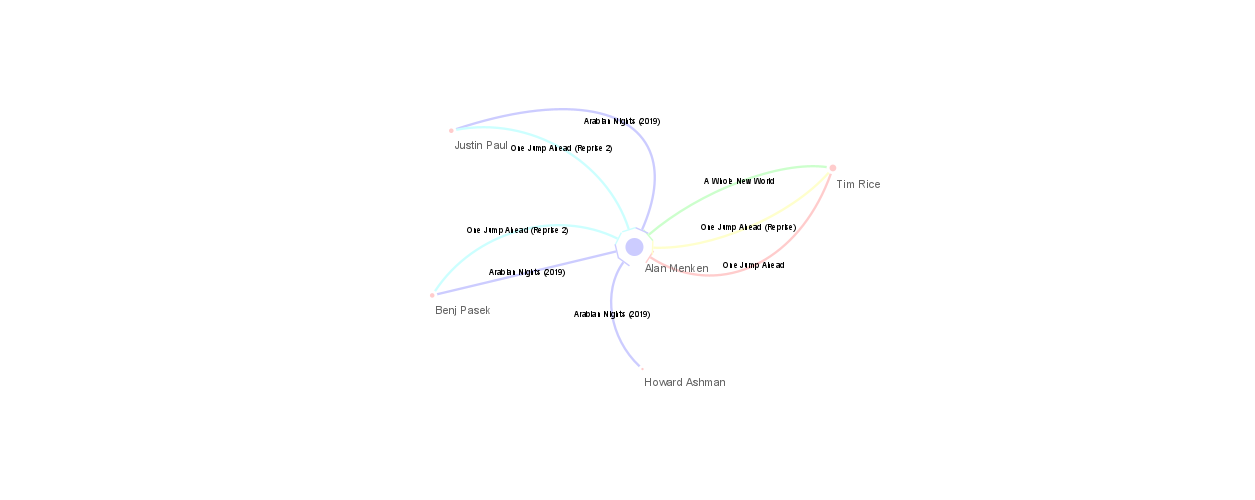
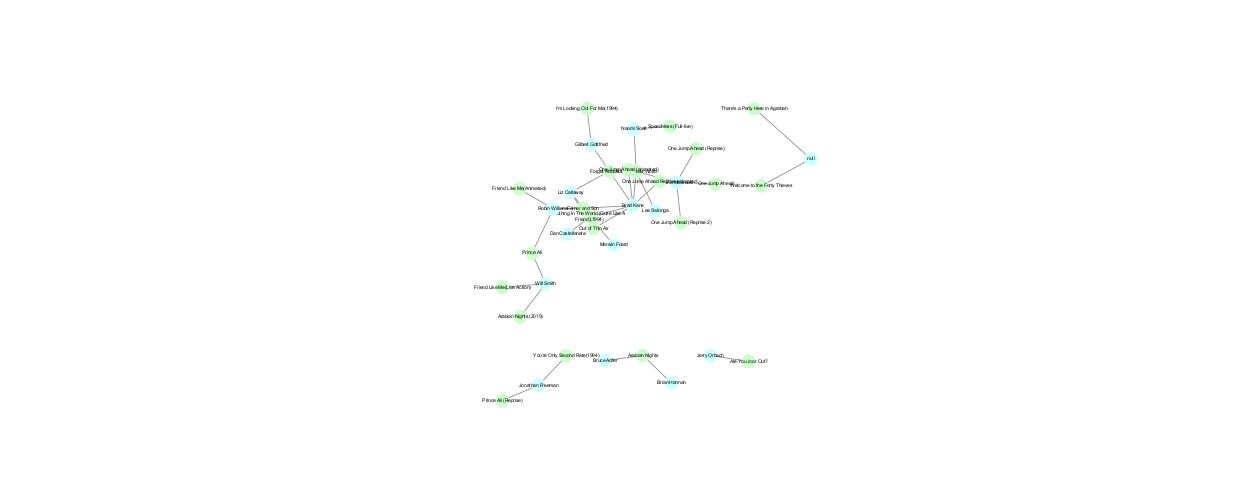
By generating these networks, we were able to see the general networks and interactions between people that worked on the songs in the Aladdin franchise. For example, Alan Menken is the composers for most of the songs in the original movie, and is also the composer of the same songs for the live-action movie. There are also pairs of composer that can be seen working together across songs in the franchise using the networks.
Natural Language Analysis
Although there were only 25 songs in our collection currently, the language used in these songs reflect a lot about the theme and overall intention of the songs, and may be deliberately chosen by the composers and Disney. For this part of our analysis, we used spaCy and Pycharm to conduct natural language processing over our entire collection, extracting interesting parts of speechs and elements in our collection to focus on.







{kind=link}